OpenAI o1: Hype vs. Reality

OpenAI's recent release of the o1 model finally solved the “strawberry” problem. Touted for its enhanced "reasoning" capabilities, o1 represents another leap in language model technology. But let's be clear: when we talk about AI "reasoning," we're not referring to human-like cognition. Instead, these models leverage vast datasets and sophisticated algorithms to recognize patterns in how people express reasoning through text.
Despite this distinction, o1's performance is impressive:
- 89th percentile on competitive programming questions
- Top 500 in USA Math Olympiad qualifier
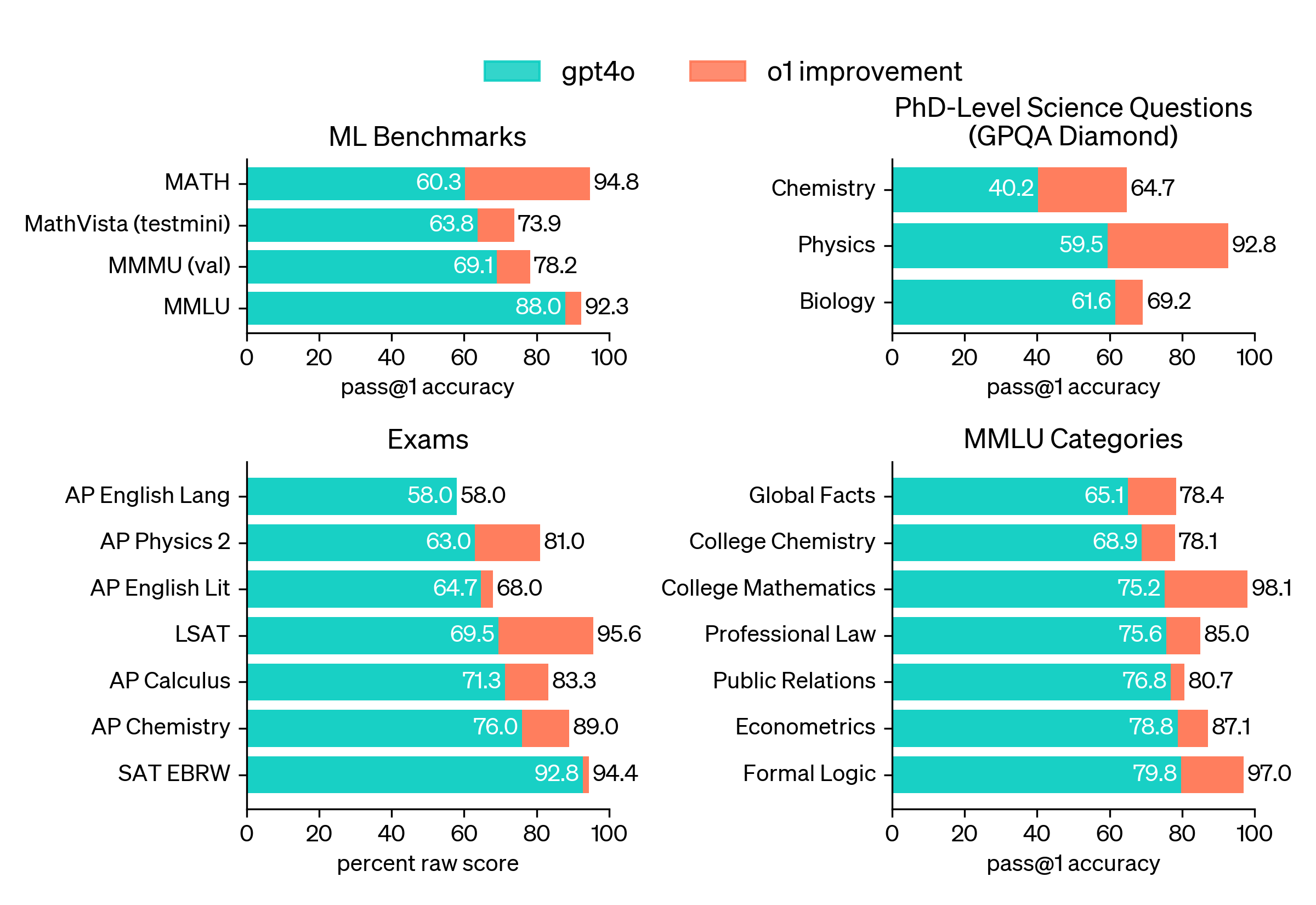
- Surpasses PhD-level accuracy on complex STEM problems
ChatArena currently ranks o1 as the #1 model for Hard Prompts, with o1-mini performing on par with its larger counterpart, o1-preview.
As we dive into o1's capabilities, I'll share insights from my recent experiments, comparing them with other leading models like GPT-4 and Claude 3.5 Sonnet. But first, an exciting update from Mellonhead:
Mellonhead's AI Learning Opportunity

I'm excited to invite you to our upcoming course, "Getting More From Generative AI." This four-part series will supercharge your ability to innovate, communicate, and analyze using AI tools. It starts in 2 weeks, and you can attend it live or offline. Register here.
Still not sure? Join a free 30-minute lightning lesson on "Brainstorming with Generative AI" next Tuesday, 10/15, at 9:30 am PT to get a preview of the course and level up your GenAI skills. Sign up here.
OpenAI o1 Capabilities
OpenAI positions o1 as a model distinct from the GPT family of models. It’s not a successor to GPT-4o; it’s in its own class. And that class is all about reasoning and problem-solving, specifically for coding, math, and, to an extent, science.
But just as people are getting used to o1, and in the 3 weeks it took me to experiment and write an article, OpenAI has already made another announcement: a feature called “canvas” that’s available as a mode for interacting with gpt-4o.
In a future article I’ll provide my thoughts on how the canvas UX compares to writing and coding with Claude and Cursor. For now, I'll focus on how well o1 can solve problems and think creatively.
My Experiments
I compared o1 with GPT-4 and Claude 3.5 Sonnet across three tasks:
- Business Case Framework - I wanted to see if I could get O1 to provide a framework that was actually helpful for navigating an organization and would provide tangible guidance for building influence. This is exactly the type of request that is easy to generate a mediocre and generic response, but a helpful output requires advanced prompting techniques.
- Webinar Communication Strategy - I wanted to see how o1 compared with questions around messaging and positioning and how it would compare short-term vs. long-term goals when developing a comms strategy.
- Content Marketing Calendar - OpenAI specifically mentions providing only the most important details in o1 prompt. I wanted to test how well o1’s responses compared when considering multiple constraints and objectives.
The results:
- I was able to create a framework that aligned with my lived experiences building and presenting business cases when I worked with GPT-4o, leveraging a panel of experts' prompting technique. o1 and sonnet-3.5 on their own were mediocre at best.
- o1 and gpt-4o delivered comparable, concise, actionable communication strategies, but sonnet-3.5 was verbose
- o1’s content calendar best adhered to my criteria and provided the greatest diversity in content. sonnet-3.5 was biased towards content with a high LOE (webinars, organizing forums, etc.) despite instructions that there is only one part-time marketing resource for content.
My raw notes have full prompts but are messy. You can view them here.
The Verdict
The final score:
- ChatGPT 4o: 2
- ChatGPT o1: 2
- Claude sonnet-3.5: 0
Claude, which I’ve really come to love over the last six months, performed poorly, and as a result, I’ve now re-engaged with ChatGPT on a daily basis. A continued reminder of the importance of continued experimentation with this rapidly evolving technology.
I still don’t know the best ways to prompt o1 - I suspect identifying how and when to use it compared to 4o is something we’ll better understand in six months.
But of course, by then, we’ll have another model to try out.
It's the end of the year - if you have budget to spend and you're not getting the results you want from your AI tools, hire me! I work deep with teams as an in-house AI advisor and facilitate hands-on GenAI workshops. Email mariena@mellonhead.co or grab time on my calendar.